HW2: MAT 321 - Numerical Analysis and Scientific Computing.¶
- You can (and probably should) discuss assignments with others, the AI's and me, but you must write and understand any solutions/code that you submit. This rule should be followed in good faith and with adherence to the Honor Code.
- You must upload the assignment to Canvas before the deadline.
- All the code you hand in should be contained in this notebook. The written solutions can be either typed up in the notebook (preferred) or hand written and handed in through Canvas as well.
Disclaimer: this homework has a lot of text but most of it is background. There is also a lot of code, but most of it is provided for you. Each function you have to complete is indicated by
ADD YOUR CODE HERE¶
You should try to understand what the rest of the code does, but you may assume you don't have to change the code. See precept 2 for the syntax of matrix operations if you need it.
Problem 1: Poisson's equation¶
The latter part of the class is focused on differential equations, but we have already everything we need to design our first numerical ODE solver. In this problem, we derive a numerical scheme to approximate the solution for Poisson's equation in 1D:
$$ - \frac{d^2}{dx^2} u(x) = f(x) \qquad u(0) = u(1) = 0 $$
Here, $f(x)$ is given, and we are seeking $u(x)$. Our first goal is to discretize the differential operator $ \frac{d^2}{dx^2}$. We can do this using finite differences.
1.1¶
Your first task is to show the central finite difference scheme below is second-order accurate, that is:
$$ D^2_h u(x) := \frac{u(x + h) - 2u(x) + u(x- h)}{h^2} = u''(x) + \mathcal{O}(h^2) $$
Write your solutions here¶
1.2¶
We will discretize the interval [0,1] with the following n+2 points: $x_j = jh $, $h = 1/(n+1)$ and write the function values of $u(x_j)$ for $j =1 \dots n$ in a vector $v$:
$$ v = \begin{bmatrix} u(x_1) \\ u(x_2) \\ \vdots \\ u(x_n) \end{bmatrix} \in \mathbb{R}^{n} $$
Before we try to solve the ODE, let us consider a simpler problem: given the vector $v$ above, and assuming $ u(0) = u(1) = 0 $, find a matrix $T \in \mathbb{R}^{n\times n}$ that computes the vector:
$$ T v = \begin{bmatrix} - D^2_h u(x_1) \\ - D^2_h u(x_2) \\ \vdots \\ - D^2_h u(x_n) \end{bmatrix} \in \mathbb{R}^{n} $$
Your task is to implement the function that constructs the matrix $T$ in the code below (and make sure it passes the tests below)
import numpy as np
import matplotlib.pyplot as plt
def get_central_diff_matrix(n):
'''
n = number of interior points, h = 1/(n+1).
'''
###ADD YOUR CODE HERE
A = np.zeros((n,n))
return A
## ALL THE CODE BELOW IS PROVIDED FOR YOU.
# Computes the grid [ 1/(n+1), 2/(n+1), ..., n/(n+1)]
def get_grid(n):
return np.linspace(start = 0, stop = 1, num = n+2)[1:-1]
# Computes the grid [0, 1/(n+1), 2/(n+1), ..., n+1/(n+1)]
# A test case, u = sin(k pi x ), with known second derivative
k = 3
u_fn = lambda x : np.sin(k * np.pi * x)
f_fn = lambda x : (k*np.pi)**2 * np.sin(k * np.pi*x)
fine_n = int(1e6)
fine_grid = get_grid(fine_n)
# Plots successive finite difference discretization for increasing number of points
plt.figure()
plt.plot(fine_grid, f_fn(fine_grid), label = 'true', color = 'black')
for n in [5, 10, 20]:
A = get_central_diff_matrix(n)
grid = get_grid(n)
v = u_fn(grid)
b = A @ v
plt.plot(grid, b, '-o', alpha = 0.5, label = 'n ='+ str(n))
plt.legend()
plt.ylabel('$-d^2 f(x)$')
plt.xlabel('x')
plt.title('-$d^2f$ and its approximations')
# Plot error as a function of n
ns = np.logspace(2, 4, 10).astype(int)
errors = np.zeros(10)
for idx, n in enumerate(ns):
h = 1 / (n + 1)
A = get_central_diff_matrix(n)
grid = get_grid(n)
u = u_fn(grid)
b = A @ u
exact_df2 = f_fn(grid)
errors[idx] = np.max(np.abs(exact_df2 - b))
hs = 1 / ( ns + 1)
plt.figure()
plt.loglog( hs, errors, label = 'error')
# Make a line with slope O(h^2), that intersect the timing plot at last index
# The error should decay at the same rate at this line.
line = hs**2
scale = errors[0] / line[0]
plt.loglog( hs, scale * line, '--', label = 'O(h^2)')
plt.legend()
plt.ylabel('$e(h) = |u'' - D_h^2 u|_{inf}$')
plt.xlabel('h')
plt.gca().invert_xaxis()


1.3¶
If, instead, we are given a vector of values of the second derivatives $f(x) = -u_{xx}(x)$ and are seeking approximate values of $u(x)$, we can solve the linear system $Tv_h = b$, where
$$ b = \begin{bmatrix} f(x_1)\\ f(x_2)\\ \vdots\\ f(x_n)\\ \end{bmatrix} $$
to get an approximate solution $v_h$ such that $u(x_i) \approx [v_h]_i$ to the ODE. Note that the boundary conditions $u(0) = u(1)=0 $ are implicitly imposed by the way we built the matrix. This technique to approximate the solution of a differential equation is called the finite-difference method.
In the previous part, we were computing $-u_{xx}(x)$ approximately using samples of $u(x)$ and the Taylor reminder theorem guarantees that the error in the $\infty$-norm will decay as $\mathcal{O}(h^2)$. This problem is more difficult: we are seeking the values of $u$ from its second derivative $u_{xx}$. The Taylor reminder theorem says nothing about this case, but in fact the error also decays $\mathcal{O}(h^2)$, assuming the function is smooth enough. Time permitting, we will prove this in the later part of the class but for now, we want to demonstrate it numerically. If you are interested in the proof, see Chapter 13 of Sulli and Mayer.
Your task is to solve the ODE using the finite difference method, and make a convergence plot similar to the one above by computing the $\infty$-norm of the error (that is, $e_h = \max_i |(v_h)_i - u(x_i)|$) and showing that it decreases as $\mathcal{O}(h^2)$. To solve the linear system, you may call np.linalg.solve(). (In the coming weeks, we will see that there are much faster algorithm to solve this system than the general one implemented in np.linalg.solve(). ) We test this with the simple right-hand side $f(x) = -9 \pi^2 \sin(3 \pi x)$ defined above so that we can easily monitor the error, but this applies to any sufficiently smooth function $f(x)$.
n_tests = 10
ns = np.logspace(2, 4, n_tests).astype(int)
errors = np.zeros(n_tests)
### ADD YOUR CODE HERE
for idx, n in enumerate(ns):
# Solve ODE of with grid size n.
# Compute relative error in the solution
errors[idx] = 0
# produce a log-log scaling plot
# As above, plot a line O(h^2)
Problem 2: Fast matvecs¶
We showed in class that matrix-vector multiplication with a general $n \times n $ matrix has complexity $\mathcal{O}(n^2)$. However, we can do better in many cases, e.g. if $A = u v^T$ is an outer product there is an $\mathcal{O}(n)$ algorithm. We explore other such situations here.
2.1: truncated SVD.¶
Suppose you $A_k$ is the rank-$k$ truncated SVD of A $ \in \mathbb{R}^{n \times n} $, write a code that computes $ A_k v$ for some vector $v$ in $\mathcal{O}(kn) $
import time
import numpy as np
import matplotlib.pyplot as plt
def fast_truncated_svd_matvec(Uk, Sk, Vk, x):
# Takes in:
# Uk: a nxk matrix
# Sk: a vector of length k
# Vk: a nxk matrix
# x: a vector of length n
###ADD YOUR CODE HERE
return np.zeros_like(x)
## ALL THE CODE BELOW IS PROVIDED.
def slow_truncated_svd_matvec(Uk, Sk, Vk, x):
# Takes in:
# Uk: a nxk matrix
# Sk: a vector of length k
# Vk: a nxk matrix
# x: a vector of length n
# Computes A_k x the slow way:
A_k = (Uk @ np.diag(Sk)) @ Vk.T
return A_k @ x
# Testing for correctness
n = 100
A = np.random.randn(n, n)
[U,S,Vh] = np.linalg.svd(A)
k = 10 #rank 10 truncated SVD
Uk = U[:,:k]; Sk = S[:k]; Vk = Vh[:k,:].T
x = np.random.randn(n)
error = np.linalg.norm(slow_truncated_svd_matvec(Uk, Sk, Vk, x) - fast_truncated_svd_matvec(Uk, Sk, Vk, x) ) / np.linalg.norm(slow_truncated_svd_matvec(Uk, Sk, Vk, x) )
# Should be close to machine epsilon
print('error in truncated SVD mat-vec:', error)
# Testing complexity
ns = np.logspace(3,5.5, 30).astype(int)
timing = np.zeros(30)
for n_idx,n in enumerate(ns):
# "Fake rank 10 SVD"
# These matrices may not have orthonormal columns, but for checking scaling, it doesn't matter
Uk = np.random.randn(n, 10)
Vk = np.random.randn(n, 10)
Sk = np.random.randn(10)
x = np.random.randn(n)
# Repeat 10 times for more accurate timing
st_time = time.time()
for _ in range(10):
y = fast_truncated_svd_matvec(Uk, Sk, Vk, x)
timing[n_idx] = (time.time() - st_time) / 10
# Scaling plot
plt.figure()
plt.loglog(ns, timing, label = 'timing')
scale = timing[-1] / ns[-1]
plt.loglog(ns, ns * scale, label = '$O(n)$')
plt.xlabel('n')
plt.legend()
error in truncated SVD mat-vec: 1.0
<matplotlib.legend.Legend at 0x136291970>

2.2: Circulant matrices¶
The Discrete Fourier Transform (DFT) of a vector $x \in \mathbb{C}^n$ is the vector $y\in \mathbb{C}^n$ defined by:
$$ y_k = \sum_{j=0}^{n-1} x_j \exp(-i2\pi k j / n ) $$
(Here, vectors are 0-indexed) In other words, it is the result of the matrix-vector multiply $Fx$ between the matrix
$$ F = \begin{bmatrix} 1 & 1 & 1 & 1 & \cdots & 1 \\ 1 & \omega & \omega^2 & \omega^3 & \cdots & \omega^{n-1} \\ 1 & \omega^2 & \omega^4 & \omega^6 & \cdots & \omega^{2(n-1)} \\ 1 & \omega^3 & \omega^6 & \omega^9 & \cdots & \omega^{2(n-1)} \\ \vdots & \vdots & \vdots & \vdots & \ddots & \ddots \\ 1 & \omega^{n-1} & \omega^{2(n-1)} & \omega^{3(n-1)} & \cdots & \omega^{(n-1)(n-1)} \\ \end{bmatrix} $$
where $\omega = \exp(-i 2 \pi / n) $, $i^2 = -1$, and the vector
$$ x = \begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_{n-1} \end{bmatrix} \ . $$
The fast Fourier transform (FFT) [Cooley–Tukey,1961] is an algorithm that computes the vector $Fx$ in $\mathcal{O}(n \log n) $ operations. The FFT has been described as "the most important numerical algorithm of our lifetime" due its wide ranging applications in science and engineering. We will derive and implement the FFT in a later homework, but for now we will treat is as a blackbox that computes the matrix-vector product $Fx$ fast. In python, it can be computed by: np.fft.fft(x). Similarly, the inverse FFT that computes $F^{-1}x$ can be computed by np.fft.ifft(x).
Circulant matrices are square matrices in which all row vectors are composed of the same elements and each row vector is rotated one element to the right relative to the preceding row vector. They describe a periodic discrete convolution. For example, a $5 \times 5$ circulant matrix takes the form:
$$ C = \qquad\begin{bmatrix} c_0 & c_4 & c_3 & c_2 & c_1 \\ c_1 & c_0 & c_4 & c_3 & c_2 \\ c_2 & c_1 & c_0 & c_4 & c_3 \\ c_3 & c_2 & c_1 & c_0 & c_4 \\ c_4 & c_3 & c_2 & c_1 & c_0 \end{bmatrix} $$
The first column of $C$, $c = [ c_0, c_1, \dots c_{n -1}]$, completely describes the matrix. Circulant matrices have an amazing property: they are diagonalized by the DFT, that is:
$$ C = F^{-1} D F $$
where $D$ is diagonal, and its diagonal entries are given by $\text{diag}(D) = Fc $ (this notation means $d_{ii} = [Fc]_i$: the i-th diagonal entry of D is the i-th component of the vector $Fc$ ). We will prove this fact in a later homework. For now, your task is to use this fact and the FFT to write an algorithm that computes $Cx$ in $\mathcal{O}(n \log n )$ operations.
import scipy.linalg
def circulant_matvec(c,x):
###ADD YOUR CODE HERE
return np.zeros_like(x)
### Code below is provided for you. No need to change it
# Testing for correctness
n = 10
c = np.random.randn(n)
C = scipy.linalg.circulant(c) # Forms the n \times n circulant matrix
x = np.random.randn(n)
# C@x is an O(n^2) algorithm!
error = np.linalg.norm(C@x - circulant_matvec(c,x) )
print('error in circulant mat-vec:', error)
# Testing complexity
ns = np.logspace(3,5, 30).astype(int)
timing = np.zeros(30)
for n_idx,n in enumerate(ns):
c = np.random.randn(n)
x = np.random.randn(n)
st_time = time.time()
for _ in range(10):
y = circulant_matvec(c,x)
timing[n_idx] = (time.time() - st_time) / 10
# Scaling plot
plt.figure()
plt.loglog(ns, timing, label = 'timing')
scale = timing[-1] / (ns[-1] * np.log(ns[-1]))
# If your implementation is correct, the two lines should be roughly parallel (up to some noise)
plt.loglog(ns, ns * np.log(ns) * scale, label = '$O(n \log(n))$')
plt.legend()
error in circulant mat-vec: 5.885244950849171
<>:36: SyntaxWarning: invalid escape sequence '\l' <>:36: SyntaxWarning: invalid escape sequence '\l' /var/folders/0b/bgs7xkxj0cj4jc50c5v9hvwc0000gq/T/ipykernel_11650/2541319750.py:36: SyntaxWarning: invalid escape sequence '\l' plt.loglog(ns, ns * np.log(ns) * scale, label = '$O(n \log(n))$')
<matplotlib.legend.Legend at 0x1364c01a0>

2.3: Toeplitz matrices¶
Toeplitz matrices are matrices whose entries are constant along diagonals. They describe non-periodic discrete convolutions, and appear in many applications such as convolution neural network and numerical solution of PDEs. E.g., the following $5 \times 5$ matrix is Toeplitz:
$$ T = \qquad\begin{bmatrix} c_0 & r_1 & r_2 & r_3 & r_4 \\ c_1 & c_0 & r_1 & r_2 & r_3 \\ c_2 & c_1 & c_0 & r_1 & r_2 \\ c_3 & c_2 & c_1 & c_0 & r_1 \\ c_4 & c_3 & c_2 & c_1 & c_0 \end{bmatrix} $$
The first column $c = [c_0, c_1, \cdots d_{m-1}]$ and first row $r = [ r_0, r_1, r_2 \dots r_{n-1}]$ completely describe the a Toeplitz matrix $T \in \mathbb{R}^{m \times n}$. (Note that we must have $r_0 = c_0$)
Circulant matrices are Toeplitz, but Toeplitz matrices are not circulant! However, one can always embed an $n \times n $ Toeplitz matrix into a larger $2n \times 2n$ circulant matrix. For example, the top-left $5 \times 5$ block of the circulant matrix below is the matrix T:
$$ A = \left[ \begin{array}{ccccc|ccccc} c_0 & r_1 & r_2 & r_3 & r_4 & 0 & c_4 & c_3 & c_2 & c_1 \\ c_1 & c_0 & r_1 & r_2 & r_3 & r_4 & 0 & c_4 & c_3 & c_2 \\ c_2 & c_1 & c_0 & r_1 & r_2 & r_3 & r_4 & 0 & c_4 & c_3 \\ c_3 & c_2 & c_1 & c_0 & r_1 & r_2 & r_3 & r_4 & 0 & c_4 \\ c_4 & c_3 & c_2 & c_1 & c_0 & r_1 & r_2 & r_3 & r_4 & 0 \\ \hline 0 & c_4 & c_3 & c_2 & c_1 & c_0 & r_1 & r_2 & r_3 & r_4 \\ r_4 & 0 & c_4 & c_3 & c_2 & c_1 & c_0 & r_1 & r_2 & r_3 \\ r_3 & r_4 & 0 & c_4 & c_3 & c_2 & c_1 & c_0 & r_1 & r_2 \\ r_2 & r_3 & r_4 & 0 & c_4 & c_3 & c_2 & c_1 & c_0 & r_1 \\ r_1 & r_2 & r_3 & r_4 & 0 & c_4 & c_3 & c_2 & c_1 & c_0 \\ \end{array} \right] $$
(the lines have been added for emphasis). Using this fact, design and implement an $\mathcal{O}(n \log n)$ algorithm for matrix vector multiplication with a Toeplitz matrix $T$.
def toeplitz_matvec(c,r,x):
###ADD YOUR CODE HERE
return np.zeros_like(x)
### Code below is provided for you. No need to change it
# Testing for correctness
n = 10
c = np.random.randn(n) # First column of T
r = np.random.randn(n) # First row of T. Must have r[0] == c[0] (since they are the same entry)
r[0] = c[0]
T = scipy.linalg.toeplitz(c,r) # Forms the n \times n Toeplitz matrix
x = np.random.randn(n)
# Note that T@x is a O(n^2) algorithm once more
error = np.linalg.norm(T@x - toeplitz_matvec(c,r,x) )
print('error in Toeplitz mat-vec:', error)
# Testing complexity
ns = np.logspace(3,5, 30).astype(int)
timing = np.zeros(30)
for n_idx,n in enumerate(ns):
c = np.random.randn(n)
r = np.random.randn(n)
r[0] = c[0]
x = np.random.randn(n)
st_time = time.time()
for _ in range(10):
y = toeplitz_matvec(c,r,x)
timing[n_idx] = (time.time() - st_time) / 10
# Scaling plot
plt.figure()
plt.loglog(ns, timing, label = 'timing')
scale = timing[-1] / (ns[-1] * np.log(ns[-1]))
plt.loglog(ns, ns * np.log(ns) * scale, label = '$O(n log(n))$')
plt.legend()
error in Toeplitz mat-vec: 5.191177014108935
<matplotlib.legend.Legend at 0x1571e69f0>

2.4: Hankel matrices¶
Hankel matrices are constant along anti-diagonals (entries with the same $i+j$ are equal). For example, this $5\times5$ matrix is Hankel:
$$ H=\begin{bmatrix} c_0 & c_1 & c_2 & c_3 & c_4\\ c_1 & c_2 & c_3 & c_4 & r_1\\ c_2 & c_3 & c_4 & r_1 & r_2\\ c_3 & c_4 & r_1 & r_2 & r_3\\ c_4 & r_1 & r_2 & r_3 & r_4 \end{bmatrix},\qquad r_0=c_4. $$
A Hankel matrix $H \in \mathbb{R}^{m\times n}$ is completely determined by its first column $c$ and last row $r$ (note that we must have $c_{m-1}=r_{0}$ here).
Task: design and implement an $\mathcal{O}(n\log n)$ algorithm for matrix–vector multiplication $y = Hx$ with a Hankel matrix $H=\mathrm{hankel}(c,r) \in \mathbb{R}^{n\times n}$.
import numpy as np, time, matplotlib.pyplot as plt
import scipy.linalg
def hankel_matvec(c, r, x):
"""
Return y = H x where H = hankel(c, r), with r[0] == c[-1].
Target complexity: O(n log n).
"""
### ADD YOUR CODE HERE
return np.zeros_like(x)
# Testing for correctness
n = 10
c = np.random.randn(n) # first column of H
r = np.random.randn(n) # last row of H
r[0] = c[-1] # Hankel consistency: overlap
H = scipy.linalg.hankel(c, r) # forms the n x n Hankel matrix
x = np.random.randn(n)
err = np.linalg.norm(H @ x - hankel_matvec(c, r, x))
print('error in Hankel mat-vec:', err)
# Testing complexity
ns = np.logspace(3, 5, 30).astype(int)
timing = np.zeros_like(ns, dtype=float)
for k, n in enumerate(ns):
c = np.random.randn(n)
r = np.random.randn(n); r[0] = c[-1]
x = np.random.randn(n)
t0 = time.time()
for _ in range(10):
y = hankel_matvec(c, r, x)
timing[k] = (time.time() - t0) / 10
# Scaling plot
plt.figure()
plt.loglog(ns, timing, label='timing')
scale = timing[-1] / (ns[-1] * np.log(ns[-1]))
plt.loglog(ns, ns * np.log(ns) * scale, label=r'$O(n \log n)$')
plt.xlabel('n'); plt.ylabel('time (s)'); plt.legend(); plt.title('Hankel mat-vec scaling')
plt.show()
error in Hankel mat-vec: 7.314123156776811

Problem 3: Always a BLAS¶
In this problem we will explore the limits of our model for reasoning about the speed of algorithms. Recall that we reason about the speed of an algorithm through their complexity, by counting the number of floating point operations (flop).
BLAS (Basic Linear Algebra Subprograms) are the low-level optimized implementation of the basic linear algebra operations. They are separated into levels:
- Level 1 BLAS are vector operations that do $\mathcal{O}(n)$ flops: e.g., dot products, adding two vectors, scaling a vector.
- Level 2 BLAS are operations that do $\mathcal{O}(n^2)$ flops: matrix-vector multiply, outer product.
- Level 3 BLAS are operations that do $\mathcal{O}(n^3)$ flops: matrix-matrix multiply (while we saw in class that there exist algorithm for matrix-matrix multiplication with better complexity, they are rarely used in practice as they are slower except for huge matrices).
One can write one matrix-matrix multiply of two $n \times n$ matrices (a level 3 BLAS operation) as $n$ matrix-vector multiplies ($n$ level 2 BLAS operations), thus one might think that they have comparable running time. This is, however, not what we see in practice. The reason for this is that BLAS level 3 operations are highly optimized and benefit from low data transfer to compute ratio. In pratice, this means that one should always use the highest level of BLAS possible, e.g., if you do many BLAS level 1 operations, try to replace them with a BLAS level 2 operation.
We will illustrate this by looking at a specific computation: computing the pairwise distances between two sets of vectors. Suppose we have two sets of points in $m$ dimensions: $\{ x_i\}_{i=1}^{n}$, $\{ y_j \}_{j=1}^{l}$, $x_i, y_j \in \mathbb{R}^m$ and we would like to compute the pairwise distance-squared between the two $d(x_i, y_j) = \| x_i - y_j \|^2$ . This operation is fundamental in data science application, e.g., for clustering.
The naive implementation of this operation with two nested for-loops (provided below) uses $n \times l$ level 1 BLAS operations, and thus has complexity $\mathcal{O}(nlm)$. Our goal is to rewrite it with higher level BLAS operations, but the complexity will remain the same.
3.1:¶
Your first task is to express the matrix with entries:
$$ [H]_{i,j} = \| x_i - y_j \|^2 $$
as the sum of three matrices: two rank-1 matrices and the matrix $-2X^T Y$, where $X \in \mathbb{R}^{m \times n}$ is the matrix with columns $\{x_i\}$ and $Y \in \mathbb{R}^{m \times l}$ is the matrix with column $\{y_i\}$. That is, find $u_1, v_1$ and $u_2, v_2$ such that
$$ H = u_1v_1^T + u_2 v_2^T - 2X^TY $$
Write your answer to part 3.1 in this cell (use math and words, NOT code!)¶
3.2:¶
Your second task is to implement this formula with one level 3 BLAS operations, a few (say 4) level 2 BLAS operations and at most $O(n)$ level 1 BLAS operations, and check the difference in running time. You don't have to justify your operation count but make sure it is right!
import time
import numpy as np
import matplotlib.pyplot as plt
def fast_pairwise_distance(X,Y):
# Computes the Euclidean pairwise distance between the columns of X and Y
# using high level BLAS operations
###ADD YOUR CODE HERE
return np.zeros((X.shape[1], Y.shape[1]))
### Code below is provided for you. No need to change it
def naive_pairwise_distance(X,Y):
# Computes the Euclidean pairwise distance between the columns of X and Y the slow way
B = np.zeros((X.shape[1], Y.shape[1]))
for i in range(X.shape[1]):
for j in range(Y.shape[1]):
B[i,j] = np.linalg.norm(X[:,i] - Y[:,j])**2
return B
# Testing for correctness
n, l, m = 11, 12, 13
X = np.random.randn(m,n)
Y = np.random.randn(m,l)
error = np.linalg.norm(fast_pairwise_distance(X,Y) - naive_pairwise_distance(X,Y) ) / np.linalg.norm(naive_pairwise_distance(X,Y))
print('relative error in pairwise distance:', error)
# Testing for speed
n, l, m = 1000, 500, 900
X = np.random.randn(m,n)
Y = np.random.randn(m,l)
st_time = time.time()
naive_pairwise_distance(X,Y)
naive_time = time.time() - st_time
print('time for naive computation:' , naive_time)
st_time = time.time()
fast_pairwise_distance(X,Y)
fast_time = time.time() - st_time
print('time for fast computation:', fast_time)
print('Fast computation is :', naive_time / fast_time, ' faster!')
relative error in pairwise distance: 1.0
time for naive computation: 1.3081071376800537 time for fast computation: 0.0004088878631591797 Fast computation is : 3199.1830903790087 faster!
3.3: Fast image alignment¶
A related problem is image alignment, where one seeks to align two images as shown below.
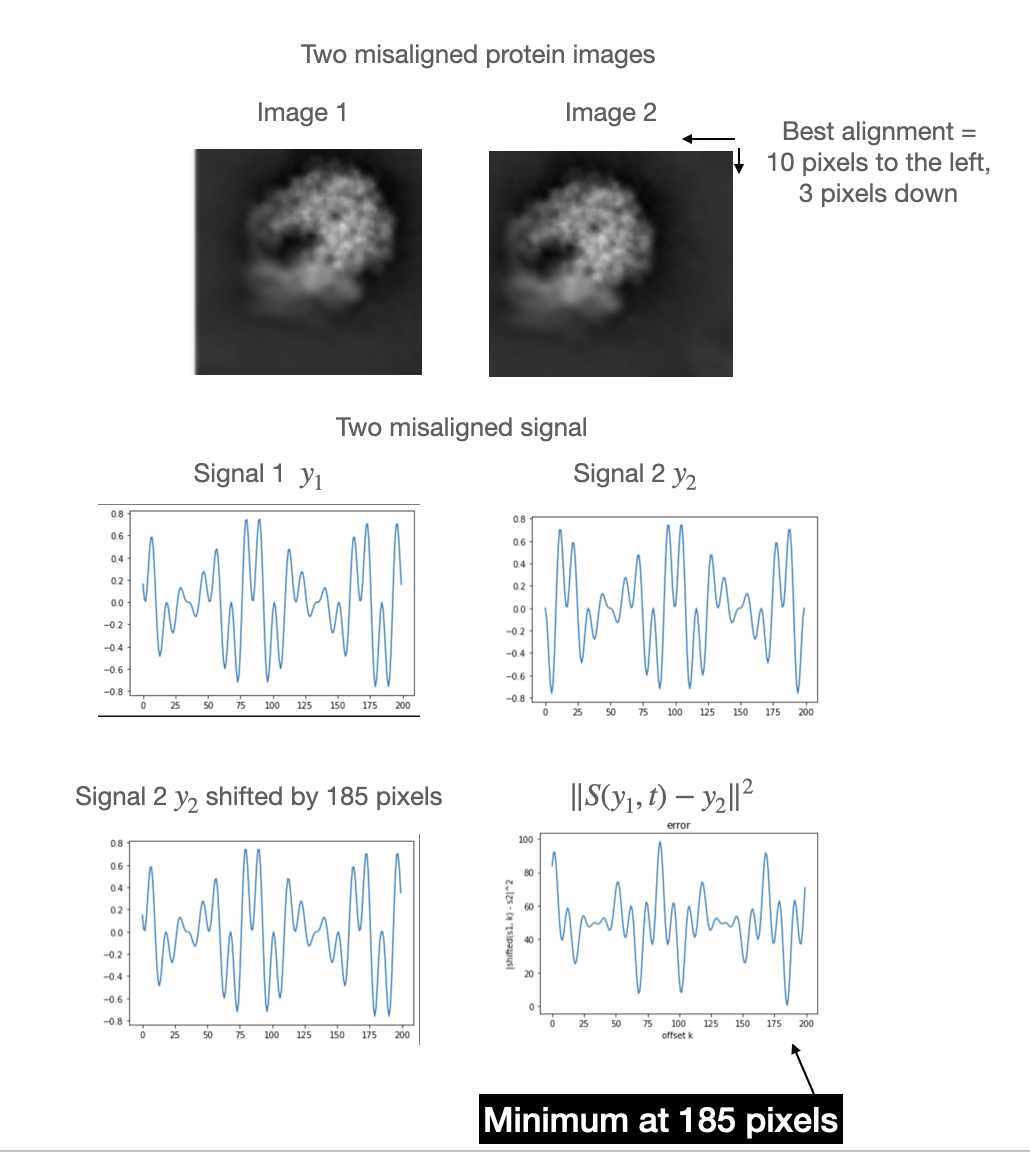
(if the image does not appear, see the image_alignment.png in your folder)
To make our life simpler, we will consider 1D signals that are periodic, but the same ideas apply to images. A natural idea to align two signals is to find the translation of one signal that results in the smallest difference between the two signals (this is illustrated in the figure). That is, we seek the translation $t$ that minimizes
$$d( S(y_1,t), y_2) = \| S(y_1,t) - y_2\|^2$$
where $S(y_1,t)$ is the operator that shifts circularly the signal by $t$ pixels. This task can get prohibitively expensive quickly for large datasets of images, so it is often important to do this computation as efficiently as possible.
Your task is to design and implement an algorithm to compute all m entries of the vector
$$ d = \begin{bmatrix} d( S(y_1,0), y_2) \\ d( S(y_1,1), y_2) \\ \vdots\\ d( S(y_1,m-1), y_2) \end{bmatrix} $$
in $\mathcal{O}(m \log m)$ operations.
def fast_translation_computation(y1, y2):
# Implement a O(n log n) method to compute
# the norm squared difference of the shifts of y1 and y2.
###ADD YOUR CODE HERE
return np.zeros(y1.size)
### Code below is provided for you. No need to change it
def naive_translation_computation(y1, y2):
m = y1.size
B = np.zeros(m)
for k in range(m):
B[k] = np.linalg.norm(np.roll(y1, k) - y2)**2
return B
# Testing for correctness
m = 10
y1 = np.random.randn(m)
y2 = np.random.randn(m)
error = np.linalg.norm(naive_translation_computation(y1,y2) - fast_translation_computation(y1,y2) ) / np.linalg.norm(naive_translation_computation(y1,y2))
print('absolute error in shifted distances:', error)
# Testing complexity
ns = np.logspace(3,5, 30).astype(int)
timing = np.zeros(30)
for n_idx,n in enumerate(ns):
y1 = np.random.randn(n)
y2 = np.random.randn(n)
st_time = time.time()
for _ in range(10):
fast_translation_computation(y1,y2)
timing[n_idx] = time.time() - st_time
# Scaling plot
plt.figure()
plt.loglog(ns, timing, label = 'timing')
scale = timing[-1] / (ns[-1] * np.log(ns[-1]))
plt.loglog(ns, ns * np.log(ns) * scale, label = '$O(n \log(n))$')
plt.legend()
absolute error in shifted distances: 1.0
<>:42: SyntaxWarning: invalid escape sequence '\l' <>:42: SyntaxWarning: invalid escape sequence '\l' /var/folders/0b/bgs7xkxj0cj4jc50c5v9hvwc0000gq/T/ipykernel_11650/90526894.py:42: SyntaxWarning: invalid escape sequence '\l' plt.loglog(ns, ns * np.log(ns) * scale, label = '$O(n \log(n))$')
<matplotlib.legend.Legend at 0x16a1ea0f0>

Q4: Givens rotations¶
A $2 \times 2$ Givens rotation is rotation matrix (thus, also an orthogonal matrix) built to zero out the second entry of a vector in $\mathbb{R}^2$. That is, provided a fixed $x = [x_1, x_2]^T$, a Givens rotation has the action:
$$G \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} r \\ 0 \end{bmatrix},$$ where $r =\|x\|= \sqrt{x_1^2 + x_2^2} $. The matrix $G$ is given by:
$$ G = \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} $$
where $\cos(\theta) = \frac{x_1}{r}$ and $\sin(\theta) = -\frac{x_2}{r}$. The code below implements a Givens rotation:
import numpy as np
## These is no code for you to write in this cell. Just run it.
def givens_rotation(x):
assert len(x) == 2, "Input vector must be of length 2"
r = np.hypot(x[0], x[1])
# np.hypot is more stable version of the following line
# r = np.sqrt(x[0]**2 + x[1]**2)
if r == 0:
return np.eye(2)
cos_theta = x[0] / r
sin_theta = -x[1] / r
G = np.zeros((2,2))
G[0,0] = cos_theta
G[0,1] = -sin_theta
G[1,0] = sin_theta
G[1,1] = cos_theta
return G
# Example usage:
x = np.array([3, 4])
G = givens_rotation(x)
print(G)
print(G @ x)
[[ 0.6 0.8] [-0.8 0.6]] [ 5.0000000e+00 -4.4408921e-16]
A $n\times n$ Givens rotation matrix $Q_k$, for $n\geq3$, is a matrix which is the identity except for for one $2\times2$ block on the diagonal[1], where it is a $2\times 2$ Givens rotation $G$: $$ Q_k = \begin{bmatrix} I_{k \times k} & & \\ & G & \\ & & I_{(n-k-2) \times (n-k-2)} \end{bmatrix} $$ where $I_{k \times k} \in \mathbb{R}^{k\times k}$ is the identity. (Note $Q_k$ is defined for $k = 0, 1, \dots ,n-2$). Givens rotations were initially introduced to compute the $QR$ decomposition of a general matrix, but were quickly made obsolete by Householder reflections. However, they are still used in some specific cases, such as the $QR$ decomposition of a Hessenberg matrices. An Upper Hessenberg matrix is a matrix where all elements below the first subdiagonal are zeros: $$ H = \begin{bmatrix} h_{11} & h_{12} & h_{13} & \dots & h_{1,n-2} & h_{1,n-1} & h_{1n} \\ h_{21} & h_{22} & h_{23} & \dots & h_{2,n-2} & h_{2,n-1} & h_{2n} \\ 0 & h_{32} & h_{33} & \dots & h_{3,n-2} & h_{3,n-1} & h_{3n} \\ 0 & 0 & h_{43} & \dots & h_{4,n-2} & h_{4,n-1} & h_{4n} \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & \dots & h_{n-2,n-2} & h_{n-2,n-1} & h_{n-2,n} \\ 0 & 0 & 0 & \dots & 0 & h_{n-1,n-1} & h_{n-1,n} \\ 0 & 0 & 0 & \dots & 0 & h_{n,n-1} & h_{nn} \end{bmatrix} \in \mathbb{R}^{n\times n} $$
As we will see in the coming weeks, this makes Givens rotations a crucial part of eigenvalue algorithms.
Your task is to find and implement an algorithm that computes the $QR$ decomposition of a Hessenberg matrix using a sequence of $n-1$ Givens rotations, and uses $\mathcal{O(n^2)}$ operations.
1. ^ Givens rotations are usually defined to be a little more general than this but this is good enough for us.
Q4.1 Give a brief explanation of your algorithm and justify its complexity below.¶
Write your answer here¶
4.2 Implement your algorithm in the cell below¶
To make your implementation a little simpler, you might want to use the block notation of numpy. For example, if you want to compute
$$ Q_k A = \begin{bmatrix} I_{k \times k} & & \\ & G & \\ & & I_{(n-k-2) \times (n-k-2)} \end{bmatrix} A $$
and store the result in the matrix $A$ itself, you can do it this way:
A[k:k+2,:] = G@A[k:k+2,:] which acts only on rows $k$ and $k+1$ of $A$ (here rows are $0$ indexed as in numpy). Similar notation holds to work on the columns of A.
import numpy as np
import time
import matplotlib.pyplot as plt
def hessenberg_qr(H):
## ADD YOUR CODE HERE
n = H.shape[0]
Q = np.eye(n)
R = H.copy()
for i in range(n-1):
## ADD YOUR CODE HERE
# placeholder
n = n
return Q, R
# Test for correctness
H = np.triu(np.random.rand(20), -1)
Q, R = hessenberg_qr(H)
print("Is Q orthogonal?:", np.allclose(Q.T @ Q, np.eye(Q.shape[0])))
print("Is R upper triangular?:", np.allclose(R, np.triu(R)))
print("Does Q @ R equal H?:", np.allclose(Q @ R, H))
# Test for complexity and scaling plot
# But for debugging, you can start with smaller ns
ns = [50, 100, 200, 400]
# Once you think you got the right complexity, try on this large example to make sure it has the correct scaling (if your algorithm is in fact n^3, it will take a very long time to run)
# This takes ~1s on my machine. If it takes much longer, you might not have the right complexity.
# ns = [50, 100, 200, 400, 800, 1600, 3200]
times = []
for n in ns:
H_large = np.triu(np.random.randn(n, n), -1) # Generate a random Hessenberg matrix
start_time = time.time()
Q_large, R_large = hessenberg_qr(H_large)
end_time = time.time()
times.append(end_time - start_time)
print(f"Time taken for n={n}: {end_time - start_time:.4f} seconds")
# Plotting the results
plt.figure(figsize=(10, 6))
plt.loglog(ns, times, marker='o', label='Measured time')
plt.loglog(ns, [times[-2] * (n / ns[-2])**2 for n in ns], linestyle='--', label='O(n^2) reference')
plt.xlabel('Matrix size (n)')
plt.ylabel('Time (seconds)')
plt.title('Scaling of Hessenberg QR Decomposition')
plt.legend()
plt.grid(True)
plt.show()
## Also observe the interesting sparsity pattern of the Q: matrix:
# Can you explain it?
plt.imshow(np.abs(Q)>1e-14)
plt.title("Sparsity of factor Q")
Is Q orthogonal?: True Is R upper triangular?: False Does Q @ R equal H?: True Time taken for n=50: 0.0000 seconds Time taken for n=100: 0.0000 seconds Time taken for n=200: 0.0003 seconds Time taken for n=400: 0.0001 seconds

Text(0.5, 1.0, 'Sparsity of factor Q')

Problem 5: SVD and Eigenvalue decomposition¶
For any $A\in \mathbb{R}^{n \times n}$ prove that there exists an orthogonal matrix $U\in\mathbb{R}^{n \times n}$ and symmetric positive semi-definite matrix (SPSD) $H\in \mathbb{R}^{n \times n}$ such that $$A=UH.$$ Recall that a symmetric positive semi-definite matrix is a symmetric matrix that satisfies $x^T A x \geq 0$ for all $x\in\mathbb{R}$. Hint: any SPSD can be written as $H = QDQ^T$ where $Q$ is orthogonal and $D$ is diagonal with non-negative diagonal entries. Conversely, any matrix of this form is symmetric positive semi-definite.
Recall that the condition number $\kappa_2(A)$ is defined by $\kappa_2(A) = \sigma_\text{max}/\sigma_\text{min}$ where $\sigma_\text{max}$ and $\sigma_\text{min}$ are the largest and smallest singular values of $A$. Show that the condition number $\kappa_2(Q)$ of an orthogonal matrix $Q$ is equal to $1$.
Conversely, if $\kappa_2(A) = 1$ for a matrix $A$, show that all the singular values are equal and deduce that $A$ is a scalar multiple of an orthogonal matrix.
Prove that for any induced matrix norm $\|\cdot\|$ and $A\in \mathbb{R}^{n \times n}$ $$\rho(A)\leq \|A\|,$$ where $\rho(A) = \max_{i} |\lambda_i|$ is the spectral radius of $A$ (i.e., the magnitude of the largest eigenvalue). Hint: Recall that the definition of a norm includes absolute homogeneity $ \|\alpha x\| = |\alpha| \|x\| $ where $\alpha \in \mathbb{C}$ and $x \in \mathbb{C}^n$